정보 검색 이론 수업을 듣다 MapReduce 논문에 대한 언급이 있어 개인적인 호기심으로 알아 보게 되었다. 평소 JS/TS 에서도 자주 나오는 Map/Reduce 함수를 자주 봤기에 더 호기심이 갔다.
구글이 2004년에 발표한 MapReduce: Simplified Data Processing on Large Clusters는 지금 보면 너무 당연한 이야기처럼 보이는데, 당시에는 꽤 큰 전환점이었다(교수님도 로직 자체는 단순하다고 하심 반박시 교수)
핵심은 단순하다.
대규모 데이터 처리에서 개발자는 비즈니스 로직만 쓰고, 병렬화/분산/장애복구/스케줄링은 시스템이 알아서 하자는 것이다. 논문은 이걸 map 과 reduce 라는 매우 작은 인터페이스로 설명한다.
나는 이 논문이 높은 평가를 받는 이유가 “엄청 복잡한 분산 시스템 문제를, 개발자가 만지는 인터페이스는 오히려 더 단순하게 만들었다”는 점에 있다고 생각한다.
기존 문제: 로직은 단순한데 분산 처리가 사람을 미치게 한다
논문 초반에서 구글은 이런 문제를 말한다.
웹 문서, 로그, 그래프 구조, 쿼리 통계 같은 대용량 데이터를 처리하는 계산 자체는 사실 개념적으로 단순한 경우가 많다.
그런데 실제로는 데이터를 여러 머신에 나누고, 병렬화하고, 장애를 처리하고, 네트워크 통신까지 맞추다 보면 본래 단순한 계산보다 분산 처리 코드가 더 커지는 상황이 생긴다.
이게 MapReduce가 나온 배경이다.
즉,
- 개발자는 계산 로직만 작성
- 시스템은 분산 실행을 자동 처리
이 분리가 핵심이다.
MapReduce 프로그래밍 모델
모델은 진짜 단순하다.
map(k1, v1) -> list(k2, v2)reduce(k2, list(v2)) -> list(v2)
map
입력 하나를 받아서 중간 key/value 여러 개를 만든다.
reduce
같은 key를 가진 값들을 모아 합치거나 정리해서 최종 결과를 만든다.
논문에서 제일 유명한 예시는 word count다.
문서에서 단어를 하나씩 꺼내 (word, 1)을 뿌리고, reduce에서 같은 단어의 count를 전부 더한다.
예를 들면 이런 느낌이다.
def map(doc_name, contents):
for word in contents.split():
emit_intermediate(word, 1)
def reduce(word, values):
emit(word, sum(values))이 정도만 보면 “이게 뭐가 대단하지?” 싶다.
근데 중요한 건 이 간단한 인터페이스 뒤에 수천 대 머신에서 돌아가는 분산 실행기가 붙어 있다는 점이다.
실행 구조: 논문에서 제일 중요한 그림
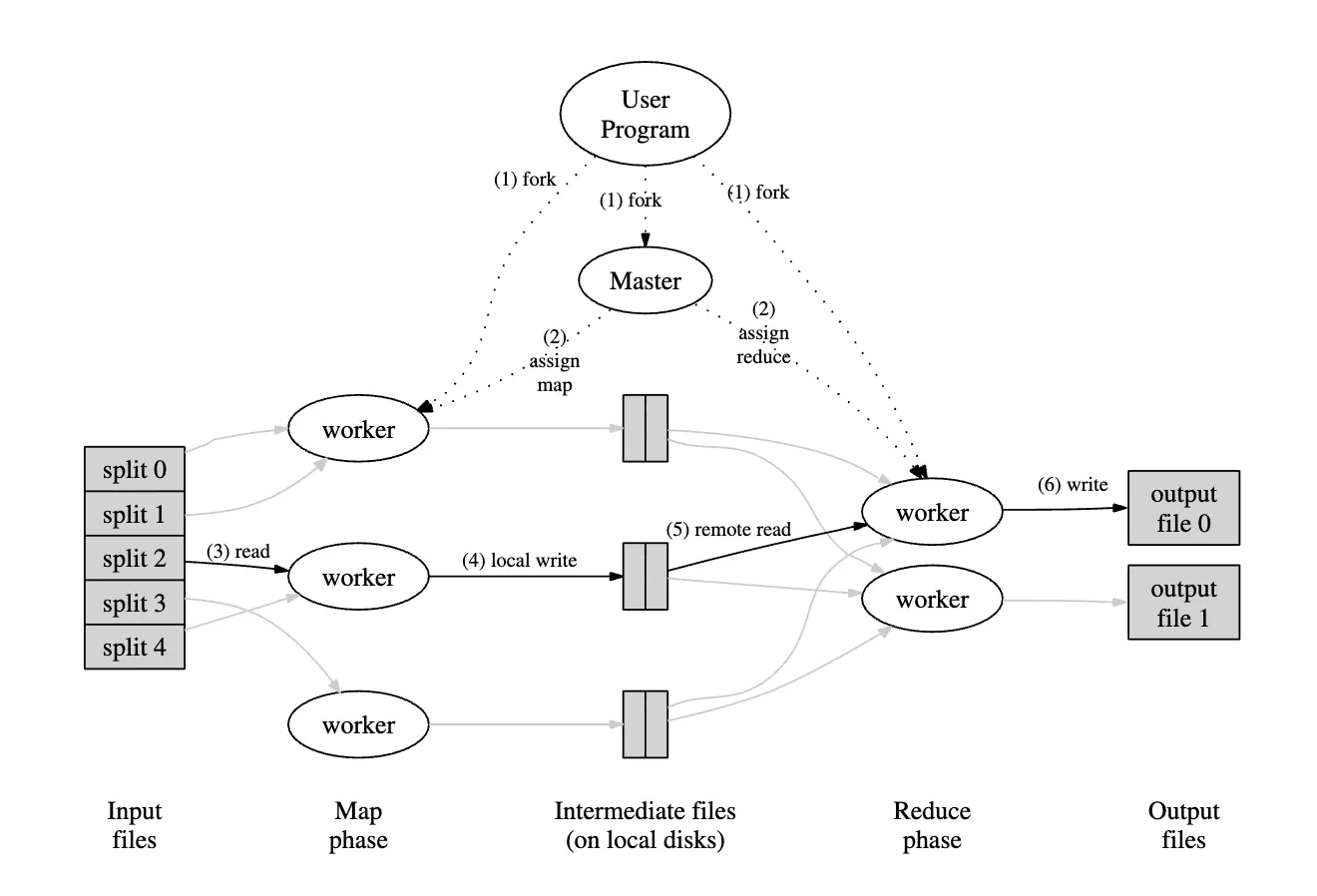 논문 Figure 1을 보면 전체 흐름이 한 번에 보인다.
논문 Figure 1을 보면 전체 흐름이 한 번에 보인다.
사용자 프로그램이 master와 worker들을 띄우고, map worker는 입력 split을 읽어 중간 파일을 만들고, reduce worker는 그 파일들을 원격으로 읽어서 최종 output file을 만든다.
흐름을 아주 단순하게 쓰면 이렇다.
- 입력 데이터를 여러 split으로 나눈다.
- 여러 map worker가 각 split을 병렬 처리한다.
- map 결과는 중간 key/value 형태로 로컬 디스크에 저장된다.
- reduce worker가 필요한 중간 데이터를 가져온다.
- key별로 정렬/그룹화 후 reduce를 수행한다.
- 최종 결과를 출력 파일들에 저장한다.
이 과정에서 중요한 것을 아래에 기술하겠다.
1. map output은 로컬 디스크에 쓴다
중간 결과를 전부 공유 스토리지에 바로 쓰는 게 아니라, map worker 로컬 디스크에 partition별로 나눠 저장한다.
그리고 master가 그 위치 정보를 reduce worker에게 알려준다.
이게 왜 좋냐면, 중간 단계의 비용을 줄이고 네트워크와 저장소 사용을 꽤 효율적으로 통제할 수 있기 때문이다.
2. reduce는 remote read를 한다
reduce worker는 필요한 중간 데이터를 각 map worker의 로컬 파일에서 가져온다.
즉, MapReduce에서 흔히 말하는 shuffle 이 이 부분이다.
3. 최종 output은 R개의 파일이다
reduce task 개수를 R이라 하면, 출력도 보통 R개로 나뉜다.
논문도 “보통 이걸 다시 하나로 합칠 필요는 없다”고 말한다. 다음 분산 작업의 입력으로 넘기면 되기 때문이다.
이 부분이 지금 봐도 인상적이다.
단일 거대 결과물보다, 분산 시스템이 다루기 좋은 형태로 결과를 남긴다는 철학이 이미 들어가 있다.
master의 역할은 생각보다 많다
MapReduce에서 master는 단순히 “감독자” 정도가 아니다.
논문에 따르면 master는
- 각 map/reduce task 상태 관리
- 어떤 worker가 어떤 task를 수행 중인지 추적
- map이 만든 intermediate region의 위치와 크기 관리
- 그 정보를 reduce worker에 전달
- 장애 감지 및 재스케줄링
을 담당한다.
즉, 데이터 plane은 worker들이 처리하지만
control plane은 master가 거의 다 쥐고 있다고 보면 된다.
대신 약점도 있다.
논문 당시 구현에서는 master가 죽으면 현재 작업을 중단한다. 체크포인트로 복구하는 건 가능하지만, 실제 구현은 master failure 시 abort한다고 적혀 있다.
논문에서는 단일 노드는 잘 죽지 않으므로 이에 대해서 크게 언급하고 있지는 않는다.
MapReduce의 무기: 장애 복구를 “재실행”으로 푼다
MapReduce는 분산 장애를 화려하게 해결하지 않는다.
그냥 다시 실행한다.
논문 초반에서도 이 모델이 re-execution을 fault tolerance의 주 메커니즘으로 사용한다고 명확히 말한다.
worker가 죽으면?
- master가 주기적으로 ping하다가 응답이 없으면 failed 처리
- 해당 worker에서 수행 중이던 task는 idle로 돌리고 다른 worker에 재할당
- map 완료 결과도 그 worker 로컬 디스크에 있었으면 다시 실행해야 함
- reduce 완료 결과는 최종 파일 시스템에 올라갔으면 다시 안 해도 됨
이 방식이 좋은 이유는 분산 환경에서 실패를 예외 상황이 아니라 기본 전제로 보기 때문이다.
수백-수천 대 머신이 있으면 언젠가 하나는 꼭 죽는다. 99.99% 라도 하루 24간 중 864초 즉 10분 이상 장애가 발생하는 것이다. 그러므로 “절대 실패하지 않게 만들자”보다 “죽어도 다시 돌리면 된다”가 더 현실적이다.
데이터 지역성(Locality): 네트워크보다 로컬 디스크가 싸다
논문은 map task를 스케줄링할 때 입력 데이터가 있는 머신에 최대한 붙여서 실행하려고 한다.
같은 머신이 안 되면 최소한 같은 네트워크 스위치 근처에 배치한다. 큰 작업에서는 이 덕분에 대부분의 입력을 로컬에서 읽고 네트워크 대역폭을 거의 쓰지 않는다고 설명한다.
이건 지금 읽어도 매우 현실적이다.
분산 시스템에서 CPU보다 더 비싼 게 종종 네트워크다.
특히 대용량 배치에서는 “연산을 데이터 쪽으로 보내는 것”이 여전히 중요한 전략이다.
논문 후반 성능 설명에서도 입력 속도가 높은 이유 중 하나로 locality optimization을 직접 언급한다.
즉 MapReduce는 단순한 API 뒤에서 이미
- compute near data
- avoid network bottleneck
- exploit locality
같은 분산 시스템 상식이 뒷받침 한다.
Refinement
논문에서 MapReduce 기본 모델 위에 붙는 refinement들을 소개하는데 아래와 같다.
1. Partitioning Function
기본은 hash(key) mod R 이지만, 사용자 정의 partition 함수를 넣을 수 있다.
예를 들어 URL이면 hostname 기준으로 같은 host 데이터를 같은 output file에 모을 수 있다.
이건 단순한 분산이 아니라 후속 처리에 유리한 데이터 배치까지 생각한 설계다.
2. Ordering Guarantees
같은 partition 내 intermediate key/value는 key 순서대로 처리된다.
그래서 정렬된 output file을 만들기 쉽다.
즉 MapReduce는 aggregation만 위한 모델이 아니라, sort-friendly한 대규모 데이터 처리 모델이기도 하다.
3. Combiner
같은 key에 대한 중간 결과를 map worker 쪽에서 먼저 부분 합쳐서 네트워크로 보내기 전에 줄인다.
논문은 이게 특정 작업에서 성능을 크게 높여준다고 설명한다.
예를 들어 word count면 (hello, 1)을 백만 개 네트워크로 보내는 대신
map 노드에서 (hello, 10000)처럼 부분 합산해서 보내는 식이다.
이건 지금 봐도 진짜 중요하다.
분산 시스템 성능은 종종 “얼마나 덜 보내느냐”로 결정된다.
4. Local Execution
분산 디버깅이 어려우니, 로컬 머신에서 순차 실행하는 대체 구현을 제공한다.
논문은 이걸 디버깅, 프로파일링, 소규모 테스트에 쓴다고 말한다.
이 부분이 개인적으로 좋았다.
좋은 분산 시스템은 “대규모에서 잘 돈다”만이 아니라 로컬에서 개발자가 테스트하기 쉬워야 한다는 걸 이미 알고 있었던 것이다.
5. Status Information / Counters
master가 HTTP status page를 제공하고, counter도 worker에서 모아서 보여준다.
지금 기준으로는 observability의 아주 초창기 형태처럼 보인다.
대규모 job은 “돌아간다”보다 지금 어디까지 됐는지, 뭐가 이상한지 보이는 것이 중요하다.
Straggler 대응: backup task가 왜 중요한가
분산 시스템에서는 전체 작업을 느리게 만드는 건 평균이 아니라 **꼬리 지연(long tail)**이다.
논문은 straggler의 예시로
- 디스크가 느린 머신
- CPU/메모리/네트워크 경쟁이 심한 머신
- 심지어 CPU 캐시가 꺼지는 초기화 버그
같은 걸 말한다. 그리고 작업 후반부에 남은 느린 task에 대해 backup execution을 추가로 띄워 먼저 끝나는 쪽을 채택한다.
이게 그냥 아이디어로만 끝나는 게 아니라, 실험 결과도 꽤 강하다.
논문에서는 backup execution 시 44% 성능향상을 이루었다고 한다.
보통 “작업 대부분이 끝났으니 거의 끝났네”라고 생각하기 쉬운데,
대규모 분산 처리에서는 마지막 몇 개가 전체 시간을 망친다.
장애 실험도 재밌다: 200개 worker를 죽여도 끝난다
논문 5.5에서는 sort 실행 중 일부 worker process를 의도적으로 죽인다.
무려 1746개 중 200개 worker process를 몇 분 뒤에 죽였는데도, scheduler가 새 worker를 띄우고 필요한 map work를 재실행해서 전체 작업은 933초 만에 끝난다. 정상 실행 대비 증가는 5% 정도였다.
이 실험이 보여주는 건 단순하다.
장애는 막는 게 아니라, 흡수하는 것이다.
MapReduce는 그걸 꽤 설득력 있게 보여준다.
![[Pasted image 20260326000727.png]]
사실 못믿겠음 내 눈으로 봐야함. 구글 석박사님이 맞습니다…
성능과 Google에서 실제 사용
논문은 grep, sort 같은 벤치마크뿐 아니라 실제 구글 내부 사용 사례도 소개한다.
MapReduce는 2003년 첫 버전 이후 빠르게 확산되었고, 2004년 8월 한 달 동안만도 29,423개의 job 이 실행되었다고 한다. 평균 job completion time은 634초, 평균 worker machines per job은 157대였고, large-scale ML, Google News/Froogle clustering, query report 추출, 웹페이지 속성 추출, large-scale graph computation 등에 사용되었다.
이 수치들이 중요한 이유는
MapReduce가 “논문용 멋진 아이디어”가 아니라 이미 조직 전체에서 실제 production abstraction으로 먹혔다는 증거이기 때문이다.
결론
결국 이 논문은 Developer Experience(DX)를 향상 시킨 구글 개발신들이 만든 것이다. 분산 시스템을 잘 만드는 것과, 분산 시스템을 쉽게 쓰게 만드는 것은 다른 문제임을 보이고 해결한 것이다.
지금 우리가 Spark, Beam, Flink, Hadoop 같은 시스템을 볼 때도
기저에는 여전히 이 논문의 질문이 남아 있다.
“분산 처리의 복잡함을 사용자 코드에서 얼마나 지워줄 수 있는가?”
그 질문에 대한 첫 번째 답변이 MapReduce였던 것 같다.
Reference
March 25, 2026