예전에는 싱글 리소스가 많았지만 이제는 많은 곳에서 멀티 리소스로 동작하는 프로그램이 많기에 멀티 프로세싱에 기반한 사고 방식을 할 수 있어야 한다.
그 과정에서 어떤 프레임워크, 툴을 쓰건 간 하드웨어의 동작 방식을 아는 것이 중요하다.
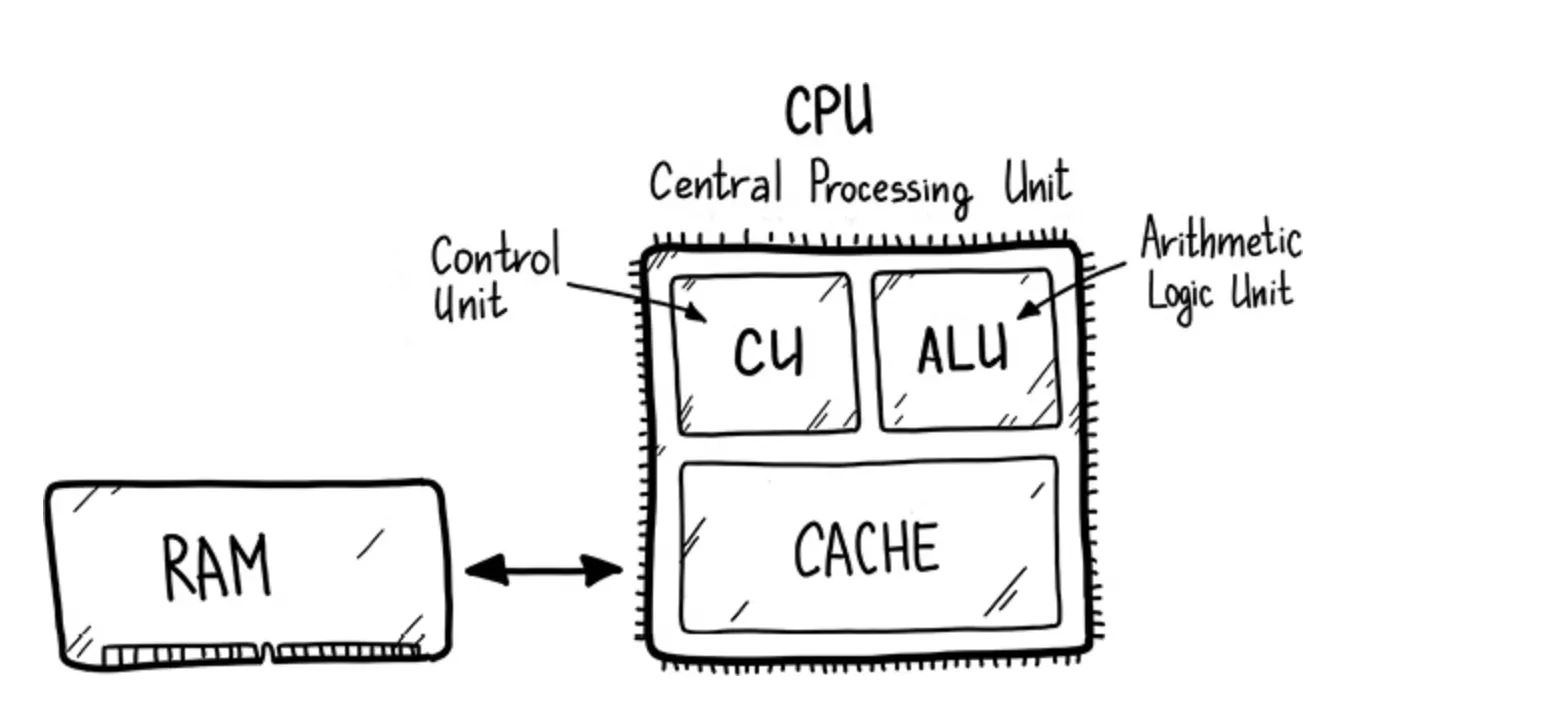
Processor
- CU: 기계어 명령어 해석 장치
- ALU: 산술처리 장치
위 두가지 구성으로 작업을 처리한다.
Cache
명령어 해석과 산술 처리를 하려면 데이터를 가져와서 작업하고 데이터를 저장해야한다. 그러면 매번 HDD/SSD 같은 곳에서 데이터를 가져오지 않고 프로그램 시작시 RAM에 모든 데이터가 올라간다.
RAM이랑 CPU와 통신보다 CPU 연산이 더빠르다. 그래서 CPU는 내부에 Cache라는 크기는 적지만 빠른 임시 저장소를 만들어 사용한다. 캐시에서 데이터가 있으면 프로세서로 전달하고 없다면 RAM -> HDD/SSD 에서 가져온다.
캐시의 레벨은 L1 -> L2 -> L3 순으로 존재한다. 레벨이 높아질 수록 용량이 많아지고 속도가 느려진다. 간혹가다 i7-5775C 같은 CPU에서 L4도 보인다. 하지만 제조 공정에서 그리고 L3 캐시를 그냥 쌓는 방식으로 L4 캐시를 사용하는 것은 잘 없는 것 같다.
CPU execution cycle
- Fetch : Control Unit(CU)는 메모리 혹은 캐시에서 명령어를 가져와 CPU로 복사. CU는 이과정에서 다양한 카운터와 함께 어떤 명령어를 가져오고 어디서 찾아야하는 지 파악한다.
- Decode: fetch된 명령어를 어떤 장치와 어떻게 작업할 껀지 분류한다.
- Excute: 계산된 명령어를 ALU로 보내고 실행 시작
- Store: 결과물 RAM 저장
프로세서는 이 사이클을 무한히 반복하며, 더 이상 가져올 명령어가 없을 때까지 계속 동작한다.
Runtime system
CPU를 직접 다루는 것은 쉽지 않다. 하드웨어 리소스 제어, 접근 관리, 프로그램 간 격리, 공유 리소스 관리 등 많은 운영 작업을 개발자가 직접 처리해야 하기 때문이다.
이런 복잡성을 해결하기 위해 애플리케이션과 시스템 사이에 추상화 계층이 도입되었는데, 이것이 런타임 시스템이다. 그 대표적인 예가 **운영 체제(OS)**다.
OS는 하드웨어와 개발자 사이의 저수준 인터페이스 역할을 하며, 이 인터페이스를 **시스템 호출(System Call)**이라고 한다. 프로그램이 디스크에 데이터를 쓰려면 OS에 위임하고, OS가 디스크 컨트롤러를 통해 처리한다. 프로그램은 디스크의 종류나 동작 방식을 알 필요가 없다.
다만 이런 추상화는 오버헤드를 수반한다. 직접 통신하지 않고 OS를 거치기 때문이다. 때로는 시스템 호출 대신 유저 애플리케이션 레벨에서 처리하는 것이 유리한 경우도 있다.
프로그램 실행 과정을 간단히 정리하면:
- 실행 파일과 정적 데이터를 메모리에 로드
main()진입점에서 프로그램 시작- OS가 프로세서 제어권을 프로그램에 이전
- OS의 제어와 보호 하에 프로그램 실행
Design of computer systems
시스템의 구조가 프로세서, RAM, 주변기기가 있고 이러한 것들이 서로 커뮤니케이트하는 system bus가 존재한다.
- user space : 유저 수준에서 어플리케이션 실행
- kernel space : OS 핵심 기능과 시스템 호출 실행
Multiple level of concurrent hardware
- Instruction-level parallelism : CPU내의 여러 ALU에 병렬적으로 동작하게 하는 것
- Bit-level parallelism : 더 깊은 Bit 레벨에서의 병렬로 컴파일러 엔지니어의 영역
멀티 프로세서와 멀티 코어
- multiprocessor : 여러개 칩 때려 박은거
- multicore processor: 모든 프로세서가 하나의 칩에 있는 것
하지만 OS는 어차피 각각의 프로세서로 인식하기에 OS 입장에서는 큰차이 없어할 수도
Symmetric multiprocessing architecture
메모리는 프로세서보다 느려서 통신비용이 발생함.
그래서 SMP라는 것을 사용한다.
SMP(Symmetric multiprocessing) : 같은 프로세서는 메모리 공유, 단일 주소공간 사용 동일한 OS에 관리됨.
프로세서 끼리 시스템 버스를 통해 상호작용을 하는 데 이러한 단점은 역시 시스템 버스를 무조건 통과해야하는 데서 오는 통신비용이 존재한다.
그래서 각 프로세서마다 Cache가 존재한다.
SMP 한계
시스템 버스에 프로세서가 많이 연결될 수록 같은 메모리를 공유하지만 캐시가 달라 캐시 일관성에 문제가 생긴다.
하지만 1980년 MESI 프로토콜이 해결함 각 캐시 라인을 보면서 모든 프로세서가 같은 캐시를 가지게 한다.
MESI에 대해서 추후 포스팅 하겠습니다..
Computer Cluster
SMP 보다 더 커진 환경에서는 어떻게 해야할 까? 여러개의 컴퓨터를 네트워크로 연결한다. 익히 우리가 알고 있는 클러스터 형태이다.
공유 메모리 체계는 없어지고 각자 로컬 머신의 분산된 메모리로 존재한다. 네트워크로 연결되어 있기에 동기화는 높은 통신 비용을 발생한다.
- Loosely coupled problem : 프로세서 간 통신이 적지만 더 많은 연산력이 필요한 경우 → 클러스터에 적합
- Tightly coupled problem : 프로세서 간 잦은 통신이 필요한 경우 → 단일 머신에 적합
클러스터는 높은 확장성이 장점이나 네트워크 통신으로 인한 높은 통신 비용이 단점이다.
Taxonomy of parallel computers - 병렬 컴퓨팅 분류
Flynn’s 의 분류 체계로 보통 나눈다. 2개의 axis 를 가지고 4가지로 분류한다.
instructions, data flow 이렇게 두가지의 기준을 사용한다.
| 분류 | 설명 | 병렬화 | 예시 |
|---|---|---|---|
| SISD | 단일 명령어, 단일 데이터 | 없음 | 초기 단일 프로세서 |
| MISD | 다중 명령어, 단일 데이터 | 없음 | (이론적) |
| SIMD | 단일 명령어, 다중 데이터 | 데이터 병렬 | GPU |
| MIMD | 다중 명령어, 다중 데이터 | 완전 병렬 | 멀티코어 CPU, 클러스터 |

MIMD가 결국 제일 많이 사용된다!
CPU vs GPU
CPU (MIMD 기반)
- 높은 클럭 속도
- 광범위한 명령어 집합
- 복잡한 순차 로직에 적합
- 코어 수가 적지만 각 코어가 강력
GPU (SIMD 기반)
- 낮은 클럭 속도
- 제한된 명령어 집합
- 수백~수천 개의 코어
- 대량의 단순 연산을 동시 처리
CPU가 GPU보다 더 복잡한 명령어를 처리할 수 있어 더 빠르지만 GPU는 제한된 명령어로 충분히 많은 코어를 활용해 병렬 처리를 통한 속도 이점을 얻을 수 있다.
CPU와의 갭을 채울 수 있다.

February 14, 2026